1. pandas 불러오기
import pandas as pd
2. pd.read_csv("data.csv")
df_ins = pd.read_csv("insurance.csv")
print(df_ins.shape) #data size
df_ins.head(10) #top 10 data print(default = 5)
3. dataframe column indexing
#dataframe column
df_ins.columns
#column select(1-column)
df_ins['age']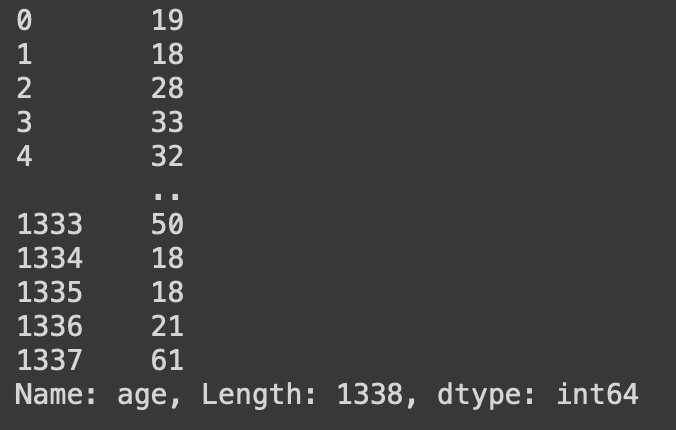
#column select(multi-column)
df_ins[['age', 'smoker','charges']]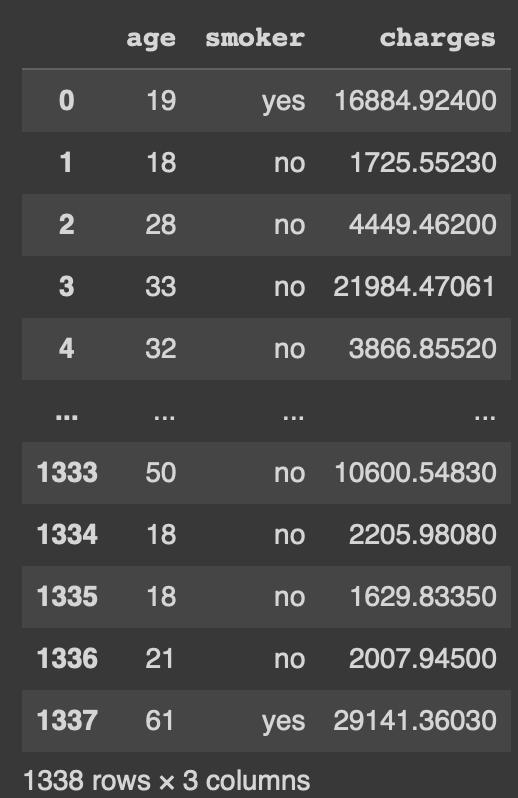
연습1) PulseRates.csv data
import pandas as pd
df_pr = pd.read_csv("PulseRates.csv")
print(df_pr.shape)
df_pr.head()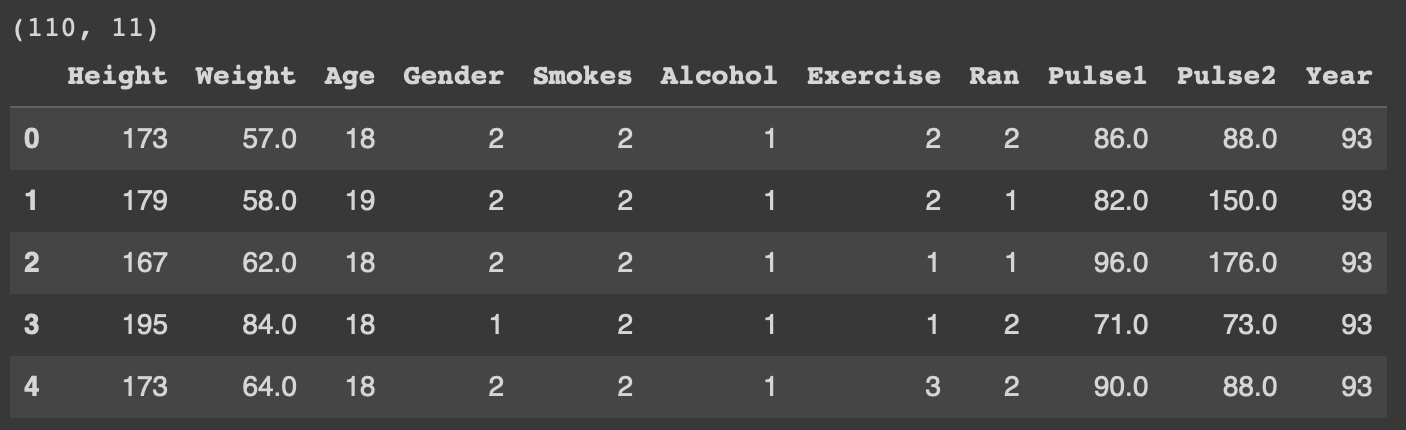
4. dataframe + condition
#dataframe with condition
df_ins['age']<30 #True&False bool type
df_ins[df_ins['age']<30] #조건에 해당하는 데이터 추출#dataframe with condition
df_ins_male = df_ins[df_ins['sex'] == 'male']
df_ins_male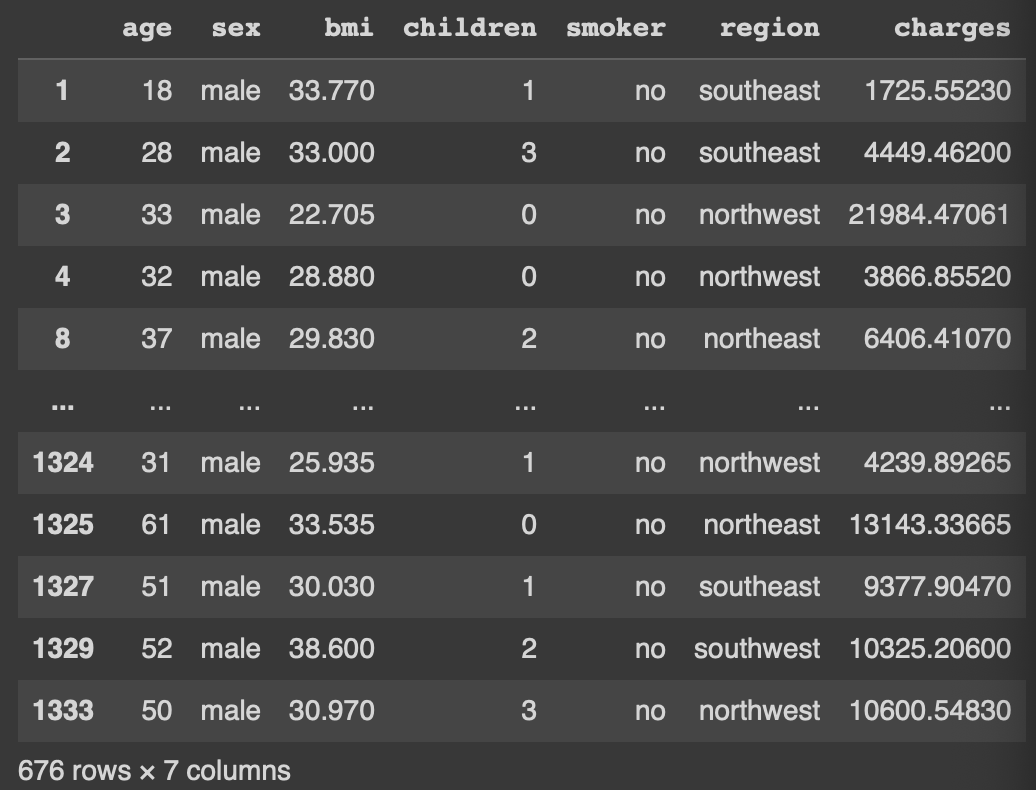
연습2)
[실습] 데이터 불러오기 및 부분 선택
- data폴더에서 StudentsPerformance.csv를 불러와서 df_sp로 저장하기
- df_sp에서 math score, reading score, writing score 세 변수 선택하기
- df_sp에서 math score가 90이상인 데이터 선택하기
- df_sp에서 gender가 'female'인 데이터 선택하기
# 1. 데이터 불러오기
import pandas as pd
df_sp = pd.read_csv('StudentsPerformance.csv')
print(df_sp.head())
df_sp.columns
# 2. 세 변수 선택하기
df_sp[['math score', 'reading score', 'writing score']]
# 3. math score 90 이상 선택하기
df_sp[df_sp['math score'] > 90]
# 4. 'female' 데이터 선택하기
df_sp[df_sp['gender']=='female']
5. DataFrame 과 Series 이해
Series)
- 일종의 리스트로 정수, 문자열, 실수 등 포함하는 1차원 배열
- 0~n의 인덱스를 가지는 리스트
- 인덱스와 함께 한 개의 리스트만 갖음
- DataFrame의 단일컬럼에 대한 데이터 구조
DataFrame)
- 메모리에 Series 데이터들로 저장이 됨
- 2차원 배열로 된 데이터 구조로 서로다른 데이터 타입을 컬럼에 저장
#Series 생성
from pandas import Series
import pandas as pd
data = {'cake' : 5000, 'choco' : 1000, 'cheese' : 2000}
obj = Series(data)
print(obj)
print(type(obj))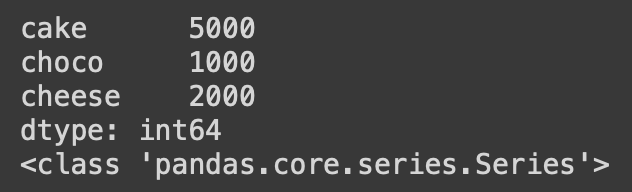
#Series 생성
tup_data = ('emilia','1997-07-30','female',False)
series_data = pd.Series(tup_data, index = ['name','birth','sex','student'])
print(series_data)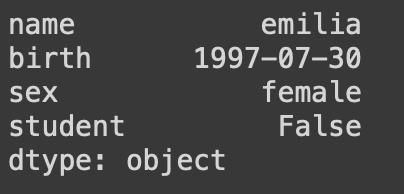
#DataFrame 생성
import pandas as pd
menu = ['cake' , 'choco', 'cheese']
price = [5000,1000,2000]
menu_series = pd.Series(menu)
price_series = pd.Series(price)
frame = {'Menu' : menu_series, 'Price' : price_series}
result = pd.DataFrame(frame)
print(result)
print(type(result))
print(result.dtypes)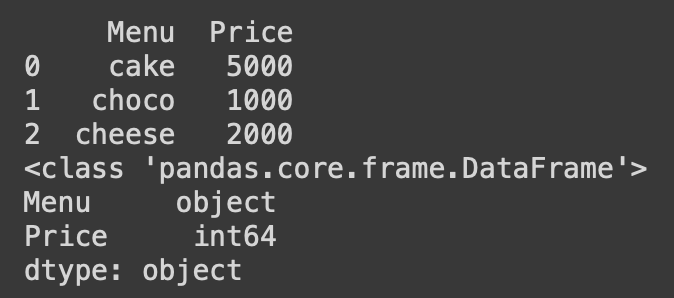
df.dtypes : dataframe 의 column별 데이터 형태를 알려줌
#DataFrame 생성
import pandas as pd
dict_data = {'A':[1,2,3],'B':[4,5,6],'C':[7,8,9],'D':[10,11,12]}
df = pd.DataFrame(dict_data)
print(type(df))
print(df)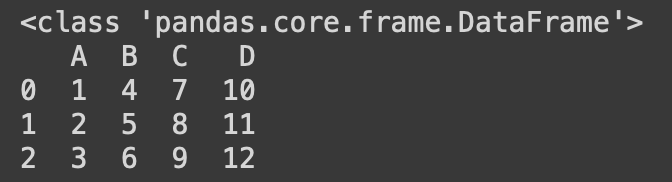
6. Data type 변환 (dtypes, set_index, reset_index, astype)
#DataFrame 생성
import pandas as pd
menu = ['cake' , 'choco', 'cheese']
price = [5000,1000,2000]
kcal = [500, 300, 100]
sugar = [50, 20, 0]
menu_series = pd.Series(menu)
price_series = pd.Series(price)
kcal_series = pd.Series(kcal)
sugar_series = pd.Series(sugar)
frame = {'Menu' : menu_series, 'Price' : price_series, 'Kcal' : kcal_series,
'Sugar' : sugar_series}
result = pd.DataFrame(frame)
print(result)
print(type(result))
print(result.dtypes)result.astype(float)
#Menu column 의 data들을 float 형태로 나타낼 수 없어서 에러 발생result.set_index('Menu', inplace = True)
result = result.astype(float)
result.reset_index(inplace = True)
result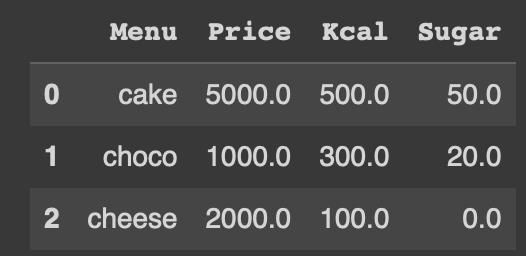
Menu column 을 index 처리 한 상태에서 모든 데이터를 float 형태로 변환
result = result.astype({'Price':int})
result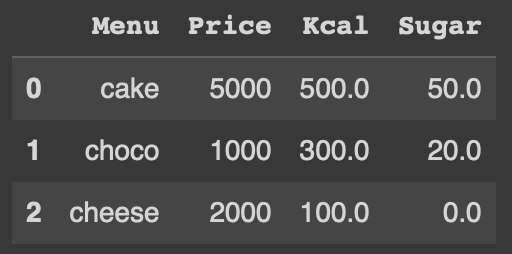
df.astype({column name : data type}) : 원하는 컬럼만 선택해서 데이터 변환 가능
7. column rename
df.rename(columns = {column name1 : column name2}, inplace = True) : name1 에서 name2 로 변경
inplace = True 가 되어있어야지 변경됨
import pandas as pd
dict_data = {'A':[1,2,3],'B':[4,5,6],'C':[7,8,9],'D':[10,11,12]}
df = pd.DataFrame(dict_data)
print(df)
df.rename(columns = {'A' : 'a', 'B' : 'b'}, inplace = True)
print('\n')
print(df)

import pandas as pd
dict_data = {'A':[1,2,3],'B':[4,5,6],'C':[7,8,9],'D':[10,11,12]}
df = pd.DataFrame(dict_data)
print(df)
df.rename(columns = lambda x: 'col_'+x , inplace = True)
print('\n')
print(df)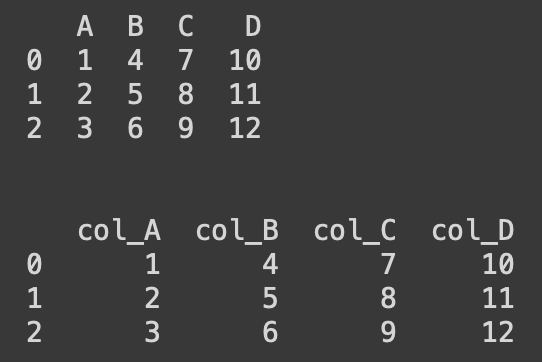
lambda x 를 써서 모든 column name을 한 번에 변경 가능
7. 행, 열 삭제 : dropna, duplicates, drop
dropna : 결측 데이터 제거
drop.duplicates : 중복 제거
df.isnull() : 결측치가 있는지 확인. 있으면 True 반환
df.isnull().sum() : 결측치 갯수 counting
df = df.dropna() : 결측치가 있는 행 삭제 (df.dropna(inplace = True), 새로 선언 안해줘도 됨)
*dropna(how = 'all') : 해당 행의 데이터가 모두 결측치일때 제거
*dropna(thresh = 2) : 해당 행의 결측치가 2개 이상인 행만 제거
*dropna(axis = 1) : 결측치가 있는 열 삭제(디폴트는 행 삭제)
*dropna(how = 'all', axis = 1) : 해당 열의 데이터가 모두 결측치일때 제거
df.duplicated().sum() : 중복된 행의 갯수 counting
df = df.drop_duplicates() : 중복된 행 삭제 (df.drop_duplicates(inplace = True), 새로 선언 안해줘도 됨)
df = df.drop([index name]) : 해당 행 삭제
+) 열 조건에 따라 행 삭제 : 조건에 해당하는 인덱스 가져와서 해당 데이터 행 삭제
# delete column by condition
import pandas as pd
dict_data = {'A':[1,2,3,4,5],'B':[4,5,6,7,8],
'C':[7,8,9,10,11],'D':[10,11,12,13,14]}
df = pd.DataFrame(dict_data)
print(df)
print('\n')
idx_nm = df[df['C'] >=10].index
result = df.drop(idx_nm)
print(result)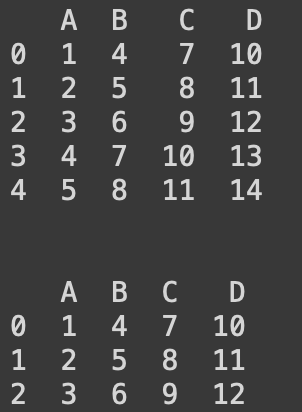
#dropna 열삭제
import numpy as np
import pandas as pd
dict_data = {'A':[1,2,3,4,5],'B':[4,5,6, np.nan, 'NaN'],
'C':[7,8,9,10,11],'D':[10,11,12,13,14]}
df = pd.DataFrame(dict_data)
print(df)
print('\n')
df.dropna(axis = 1, inplace = True)
print(df)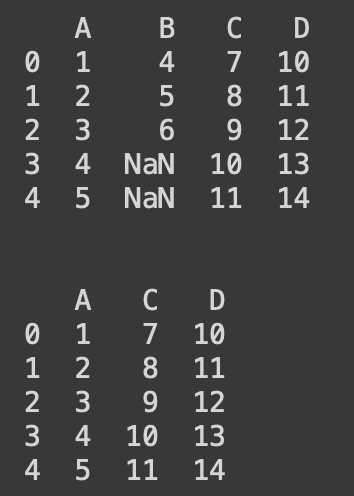
*np.nan : 결측값 임의 생성
결측값은 data analysis 에서 중요한 부분이다.
결측값 부분은 다른 글에서 따로 정리하도록 하려 한다.
(결측값 제거, 결측값 변경 등)
8. 행, 열 추가
- 행 추가
데이터 행 추가 방식에는 append(), loc[] 방식이 있는데 loc[] 방식이 좀 더 편한 방법인 것 같다.
append 방식)
ignore_index = True 설정 필요 : 기존의 인덱스를 무시한다는 선언
# 행 추가 - append
import pandas as pd
dict_data = {'A':[1,2,3,4,5],'B':[4,5,6,7,8],
'C':[7,8,9,10,11],'D':[10,11,12,13,14]}
df = pd.DataFrame(dict_data)
print(df)
new_data = {'A':6, 'B':9, 'C':12, 'D':15}
df = df.append(new_data, ignore_index = True)
print(df)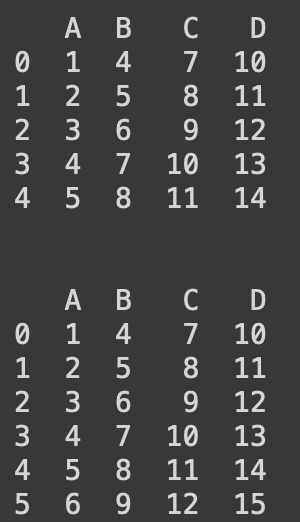
loc 방식)
*loc : 변수명(컬럼이름, 인덱스 이름)을 사용, 정확한 이름 입력 필요
*iloc : 인덱스 번호 사용
#행 추가 - loc[]
exam_data = {'name':['A','B','C']
,'math':[90,80,70], 'eng':[98,89,95],
'writing':[85,95,100], 'listening':[100,90,90]}
df = pd.DataFrame(exam_data)
df.loc[3] = 'Null'
df.loc[4] = ['D', 100,100,100,100]
df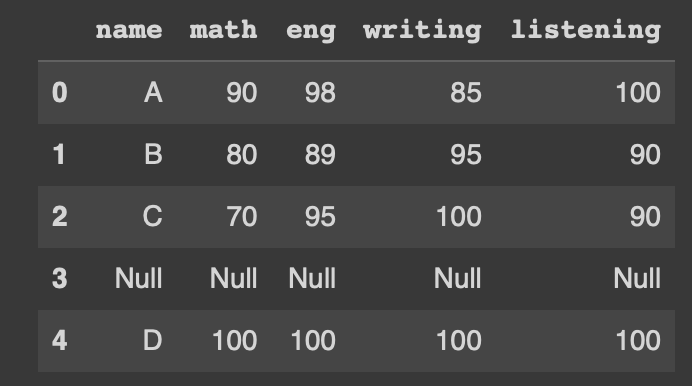
- 열 추가
#열 추가
exam_data = {'name':['A','B','C']
,'math':[90,80,70], 'eng':[98,89,95],
'writing':[85,95,100], 'listening':[100,90,90]}
df = pd.DataFrame(exam_data)
df['reading'] = [80, 90, 70]
df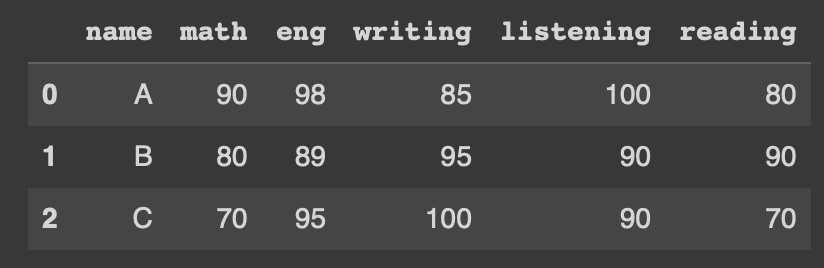
9. 전치 : df.transpose(), df.T
#transpose
exam_data = {'name':['A','B','C']
,'math':[90,80,70], 'eng':[98,89,95],
'writing':[85,95,100], 'listening':[100,90,90]}
df = pd.DataFrame(exam_data)
print(df)
print('\n')
df = df.transpose()
print(df)
#df = df.T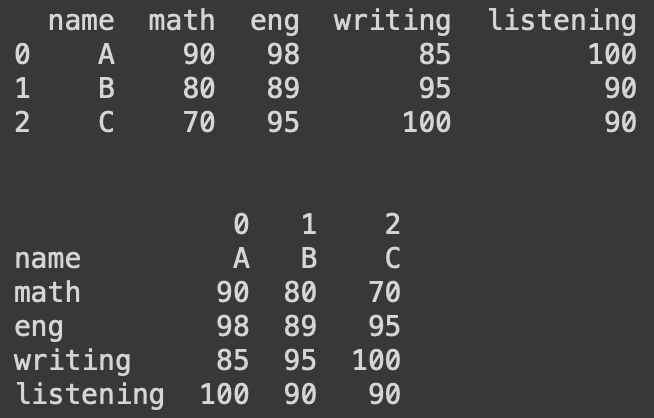
10. apply 함수 사용
- 특정 열과 행에 함수 적용
import numpy as np
import pandas as pd
np.random.seed(10)
n = 5
df = pd.DataFrame()
df['A'] = np.random.rand(n) ## random sample from standard uniform distribution
df['B'] = np.random.randn(n) ## random sample from standard normal distribution
df['C'] = np.linspace(0,5,n)
print(df)
print('\n')
#column끼리의 합
df.apply(np.sum, axis = 0)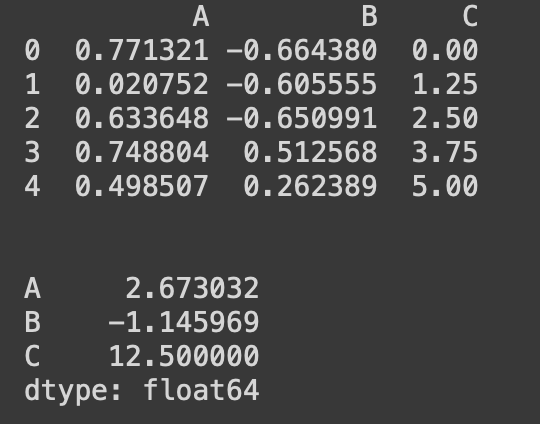
import numpy as np
import pandas as pd
np.random.seed(10)
n = 5
df = pd.DataFrame()
df['A'] = np.random.rand(n) ## random sample from standard uniform distribution
df['B'] = np.random.randn(n) ## random sample from standard normal distribution
df['C'] = np.linspace(0,5,n)
print(df)
print('\n')
# column 'A','B' 에만 square 함수 적용
print(df.apply(lambda x: np.square(x) if x.name in ['A','B'] else x))
print('\n')
# index 가 짝수인 행에만 square 함수 적용
print(df.apply(lambda x: np.square(x) if (x.name+1)%2 == 0 else x, axis = 1))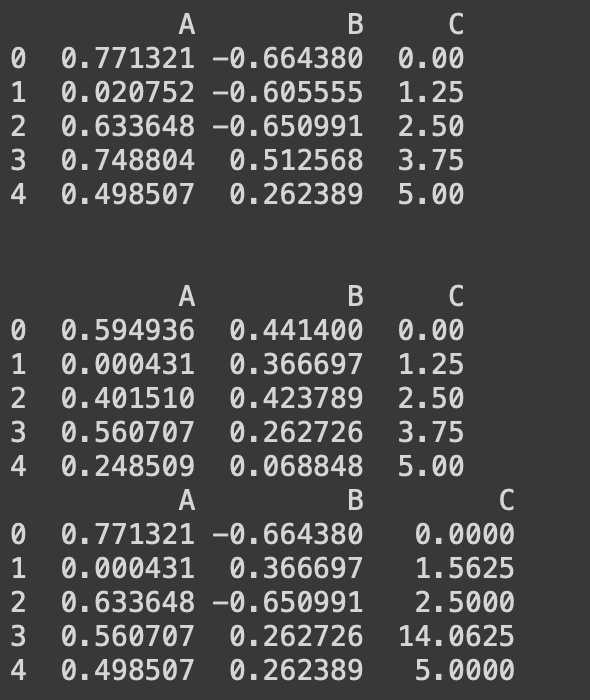
- 인자를 받는 함수 적용(argument 활용)
import numpy as np
import pandas as pd
np.random.seed(10)
n = 5
df = pd.DataFrame()
df['A'] = np.random.rand(n) ## random sample from standard uniform distribution
df['B'] = np.random.randn(n) ## random sample from standard normal distribution
df['C'] = np.linspace(0,5,n)
print(df)
print('\n')
# argument 활용하여 함수 적용
def col_sum(x,a,b):
return a*x + b
df.apply(col_sum, args = (3,1))
#같은 결과 출력코드1
arg_dict = {'a':3, 'b':1}
df.apply(col_sum, **arg_dict)
#같은 결과 출력코드2
df.apply(lambda x: col_sum(x,3,1))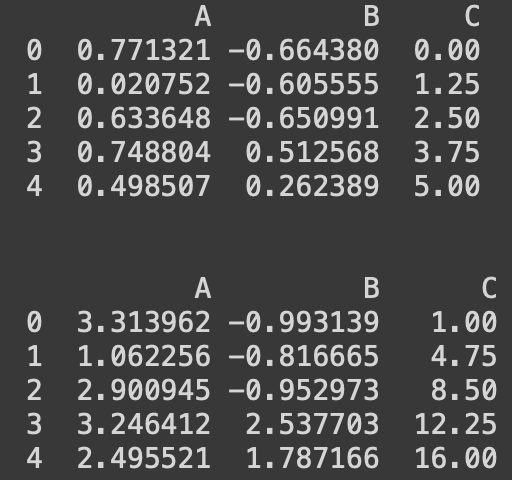
- 특정조건에 맞는 행에 함수 적용
import numpy as np
import pandas as pd
np.random.seed(10)
n = 5
df = pd.DataFrame()
df['A'] = np.random.rand(n) ## random sample from standard uniform distribution
df['B'] = np.random.randn(n) ## random sample from standard normal distribution
df['C'] = np.linspace(0,5,n)
print(df)
print('\n')
#특정조건에 해당하는 데이터에만 함수 적용
df.apply(lambda x:(np.square(x['A']), np.log(x['B']), x['C'])
if x['B']>0 else x, axis =1)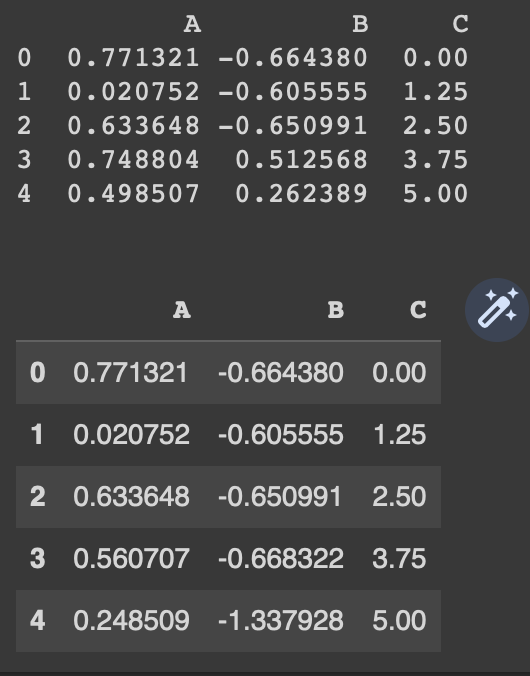
11. 데이터 병합 : concat, merge
[concat]
pd.concat([df1,df2,df3]) : 기본 옵션, 열방향 병합
pd.concat([df1,df2,df3], axis = 1) : 행방향 병합, outer join
pd.concat([df1,df2], axis = 1, join = 'inner') : 행방향 병합, inner join
pd.concat([df1,df2], axis = 1, join_axes = [df1.index]) : 행방향 병합, outer join, df1의 index는 살림
pd.concat([[df1,df2], ignore_index = True) : 기존 index 무시하고 다시 index 부여
import pandas as pd
df1 = pd.DataFrame([['A0', 'A1', 'A2', 'A3'],
['B0', 'B1', 'B2', 'B3'],
['C0', 'C1', 'C2', 'C3'],
['D0', 'D1', 'D2', 'D3']], columns=list('ABCD'))
df2 = pd.DataFrame([['A4', 'A5', 'A6', 'A7'],
['B4', 'B5', 'B6', 'B7'],
['C4', 'C5', 'C6', 'C7'],
['D4', 'D5', 'D6', 'D7']], columns=['A', 'B', 'C', 'D'], index=[4, 5, 6, 7])
df3 = pd.DataFrame([['A8', 'A9', 'A10', 'A11'],
['B8', 'B9', 'B10', 'B11'],
['C8', 'C9', 'C10', 'C11'],
['D8', 'D9', 'D10', 'D11']], columns=list('ABCD'), index=[8, 9, 10, 11])
print(df1)
print(df2)
print(df3)#열방향 병합
print(pd.concat([df1, df2, df3]))
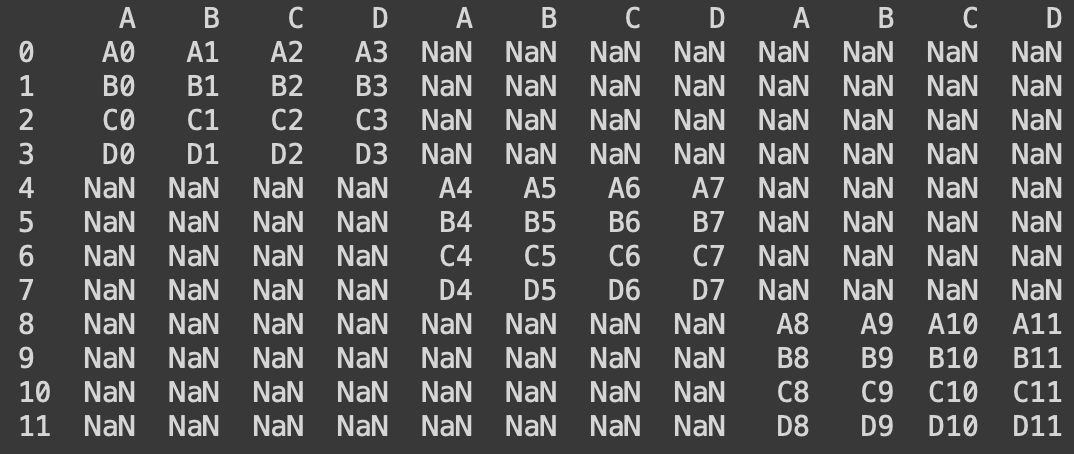
#행방향 병합 : 결측치 발생
print(pd.concat([df1, df2, df3], axis = 1))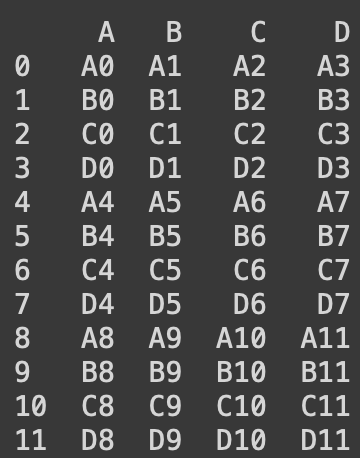
import pandas as pd
df1 = pd.DataFrame([['A0', 'A1', 'A2', 'A3'],
['B0', 'B1', 'B2', 'B3'],
['C0', 'C1', 'C2', 'C3'],
['D0', 'D1', 'D2', 'D3']], columns=list('ABCD'))
df2 = pd.DataFrame([['A4', 'A5', 'A6', 'A7'],
['B4', 'B5', 'B6', 'B7'],
['C4', 'C5', 'C6', 'C7'],
['D4', 'D5', 'D6', 'D7']], columns=['A', 'B', 'C', 'D'], index=[2, 3, 4, 5])
#행방향 병합
print(pd.concat([df1,df2], axis = 1, join = 'outer'))
print('\n')
print(pd.concat([df1,df2], axis = 1, join = 'inner'))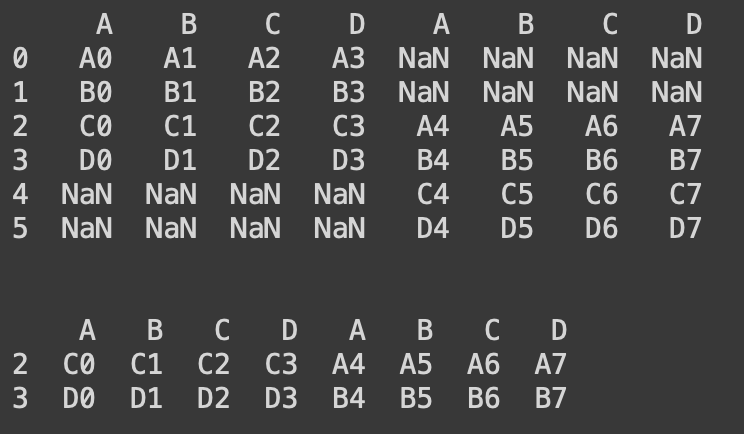
[merge]
pd.merge(left, right , on = 'key') : 공통 key를 기준으로 inner join(default = inner)
*inner join : 겹치는 것만
pd.merge(left, right, on = 'key', how = 'outer') : 공통key를 기준으로 outer join
*outer join : 첫번째 df의 key들 모두 하고 두번째 df의 key에선 안겹치는 애들만
pd.merge(left, right, on = 'key', how = 'left') : 공통key를 기준으로 첫번째 df에 맞춰 join
*df1의 key 돌면서 df2 merge해서 매칭되는 애들 다 가져옴
pd.merge(left, right, on = 'key', how = 'right') : 공통key를 기준으로 두번째 df에 맞춰 join
*df2의 key 돌면서 df1 merge해서 매칭되는 애들 다 가져옴
import pandas as pd
df1 = pd.DataFrame([['A0', 'A1', 'A2', '1'],
['B0', 'B1', 'B2', '2'],
['C0', 'C1', 'C2', '3'],
['D0', 'D1', 'D2', '4']], columns=['A','B','C','Key'])
df2 = pd.DataFrame([['1', 'E0', 'E1', 'E2'],
['2', 'F0', 'F1', 'F2'],
['3', 'G0', 'G1', 'G2'],
['4', 'H0', 'H1', 'H2']], columns=['Key','D','E','F'])
print(df1,'\n',df2)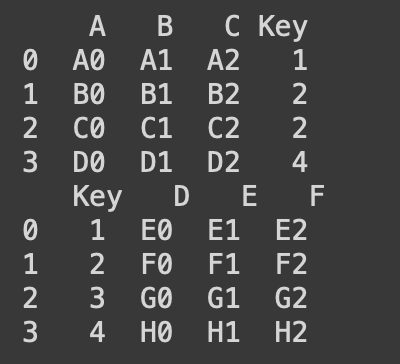
print(pd.merge(df1, df2, on = 'Key'))
print(pd.merge(df1, df2, on = 'Key', how = 'outer'))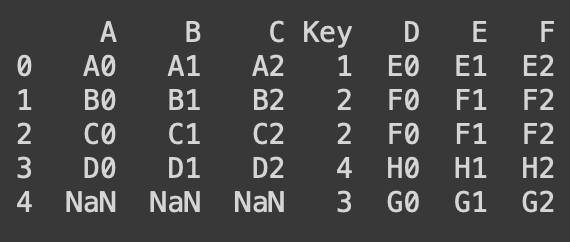
print(pd.merge(df1, df2, on = 'Key', how = 'right'))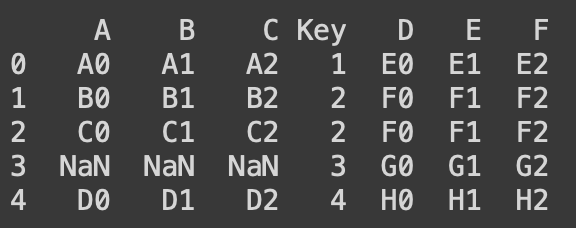
이상 DataFrame, Pandas도 끝! 하지만 아직도 너무 많은 기능들,,
추가할 사항들 생기면 업로드 예정!
다음 글은 matplotlib 활용한 데이터 시각화~
'Python > Data Analysis' 카테고리의 다른 글
| 데이터 시각화_matplotlib(1) - plt 기본 설정 (0) | 2023.05.21 |
|---|---|
| Numpy (0) | 2023.05.14 |

